
Harmonizing Application Cockpit data using DB views
As you may have read about Application Cockpit in one of our previous articles, it is “The tool which lets concerned developers quickly find their bearings and gather relevant information pertaining to a particular service running in our ecosystem”.
Over time, AUTO1 engineers and managers grew fond of using Application Cockpit, and started relying on it on a daily basis. The increase in popularity, naturally, led to development of new features, out of which, one of the arguably most impactful ones was the "dynamic service search" (or "App Cockpit Search", as we call it internally).
The challenge
AUTO1 platform currently consists of 600+ microservices, and on average two new services are created every week. Many times in the past, we needed to search our AUTO1 service inventory for services which were matching some specific criteria, e.g. are written in a specific language, using certain frameworks or libraries, or have certain features enabled.
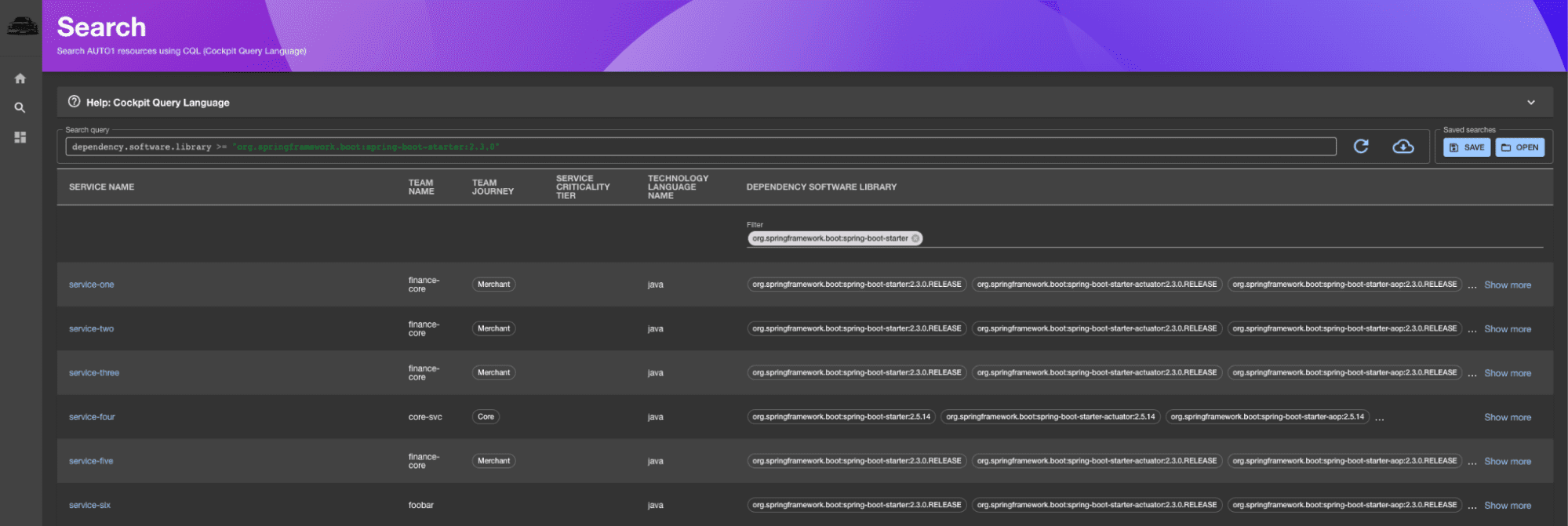
As it happens, this is actually where App Cockpit App Cockpit Search chimes in. From the user’s perspective, it is an UI that lets the user input some search criteria using the Cockpit Query Language (or CQL for short) and be presented with a list of services matching the criteria. One typical use case is searching the AUTO1 service inventory for the usage of a specific library in a specific version.
Below is an example search for services using org.springframework.boot:spring-boot-starter dependency in version 2.3.0 onwards:
The dilemma
Once we were certain of what we wanted to achieve, i.e.: search our AUTO1 service inventory using dynamically defined criteria, we began the efforts of defining the architecture.
As you may recall from our previous article about the Application Cockpit, we use Backstage as our Front-end. Backstage is fetching data from our backend-for-frontend service called “Application Cockpit Data Provider”, which in turn, is backed by a PostgreSQL DB.
As Backstage itself comes with search functionality that could be potentially used for our purposes, we were left with two options, either to reuse the already provided solution and tailor it to our needs or create a solution from scratch.
Why not reuse what is already available
After evaluating the Backstage search, which at that time, was still in the early alpha stage, it was clear to us that it would be a bumpy ride. As it is a full-blown search mechanism, or to put it more bluntly, an over-blown mechanism, compared to what we really needed:
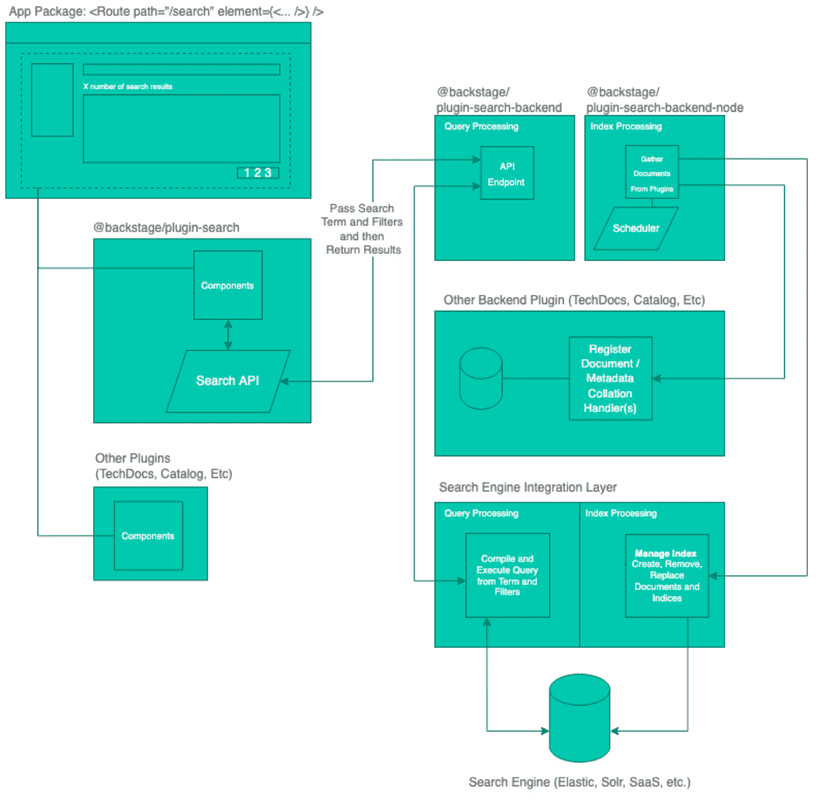
Source: backstage search architecture
-
The Backstage search was “bloated” with components that we don’t really need, due to the nature of the data and queries we planned to execute (like collators, indexers, and schedulers). As we already had our integration layer performing calculations on our data and feeding it to our UI, we didn’t need any of these.
-
At that stage, the feature-ready predefined UI components connected with the search plugin did not provide us with the required flexibility, which we managed to achieve later with the Cockpit Query Language.
-
The usage of the Backstage search would require us to fork some of the Backstage search plugins, adopt them and then maintain them ourselves. On top of that, it would require us to make adaptations also on the data structures themselves, which was something that we were not very eager to do.
Long story short, although the solution seemed to be promising and the architecture was quite neat, the shortcomings outweighed the benefits for our use cases. Hence, we pursued the idea of creating the solution from scratch.
Making our own solution
As you may recall from the Application Cockpit Model Outline article, our data model consists of only two types: Resources and Readings. The latter type comes in different shapes and sizes, as we store the actual Reading values in form of JSON objects.
Since we have different JSON schemas for different types of Readings, we need to harmonize them, in order to make them “generally” searchable and combinable to support logical query operators such as OR and AND without changing the actual stored data structures.
As a simple example, where we would like to search all services built on a specific version of a docker base image, which is implemented on top of a Spring 5 Framework, where the main programming language is Java. In terms of data structures, this is how it would be represented:
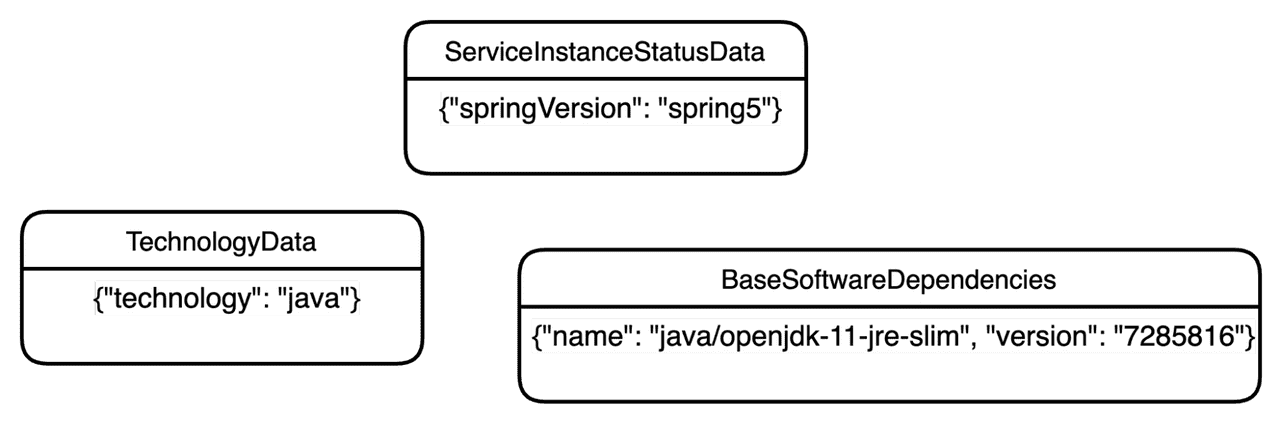
As we already use Spring Data JPA as the persistence layer to communicate with PostgreSQL in our data provider service, we have limited our options to two choices: dynamically built queries on top of joined database tables or database views. Either of them seemed to us, initially, as a good candidate for dealing with the complexity that stems from the heterogeneous data structures.
Dynamically built queries
The idea behind this solution was to create a set of SQL queries, backed by corresponding Spring Data JPA repositories, one for each attribute in question, execute these queries against the DB, and then combine the results on the Java side performing the necessary filtering and aggregation.
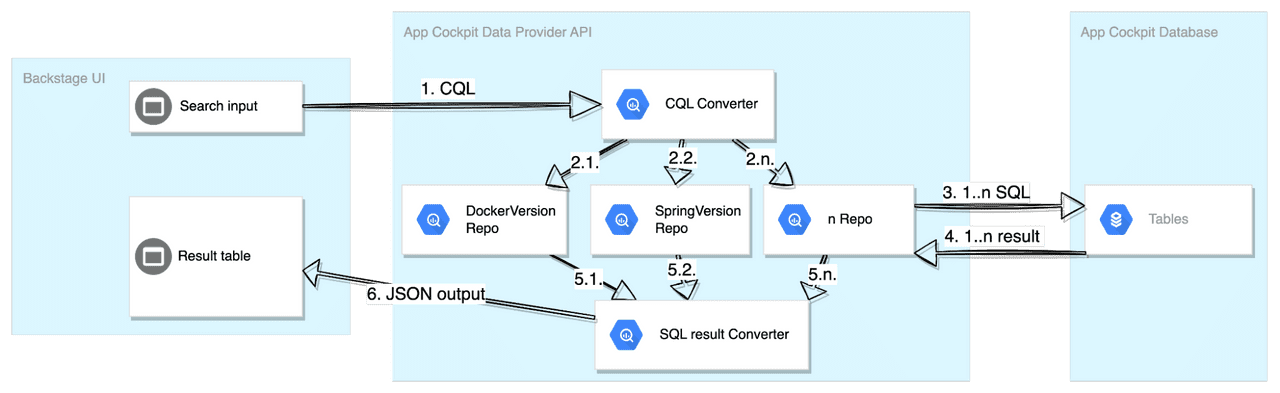
The advantage of this solution was that we would keep things small and isolated. Each query is in a separate repository. Each one would deal just with the data structures it's aware of. On the other hand, this solution would come with a significant performance penalty, due to the substantial amount of data that would be transferred from the DB, just to be later filtered out on the application side.
The alternative solution would be to dynamically build a large SQL query that would perform both the retrieval of the data and the filtering and aggregation of its results.
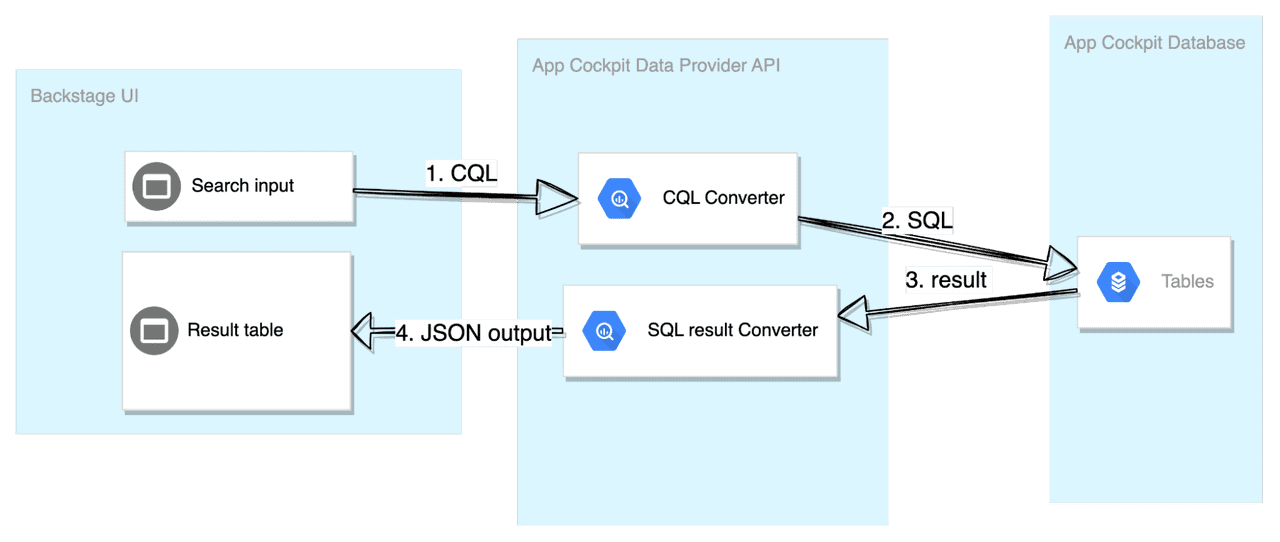
However, this approach would come at an increased maintenance cost. As every data structure change would require a corresponding Java code change, hence we would lose the benefits of having the data values stored in the JSON objects. On top of that, maintaining a large SQL query would quickly become a problem on its own.
Database views
Knowing the shortcomings of the dynamically built queries, we decided to evaluate another promising approach - the database views, that could hide the complexity of dealing with the heterogeneous data structures:
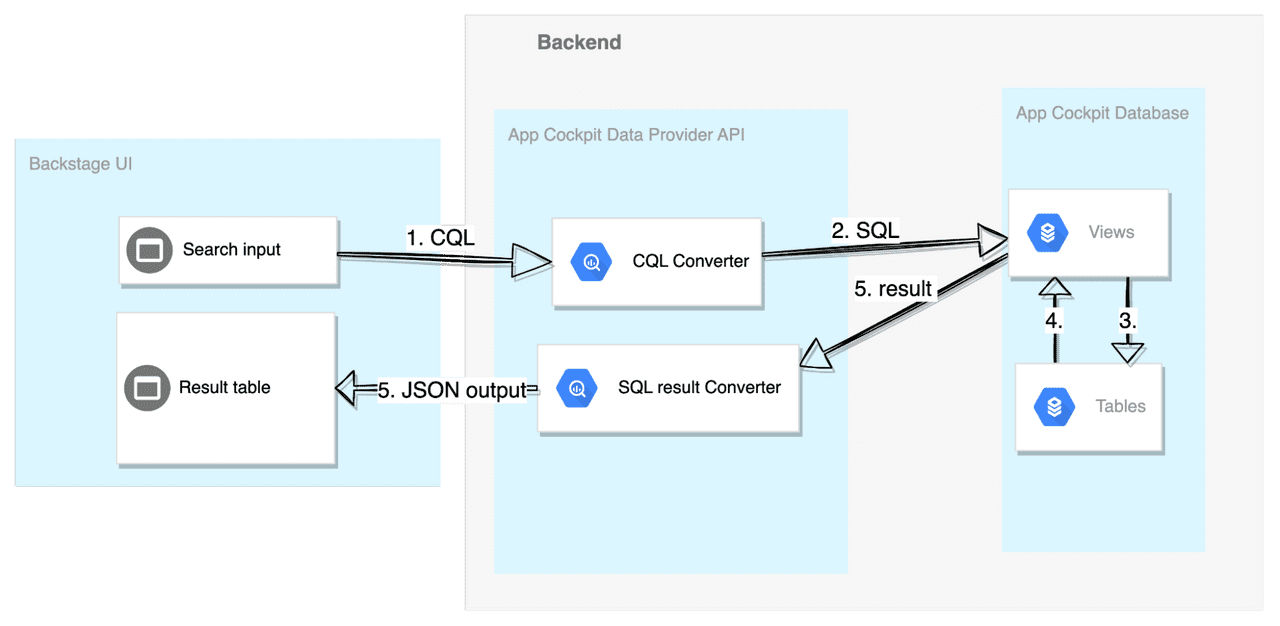
In that approach, we would create a database view that could look like the following (based on our previous example):
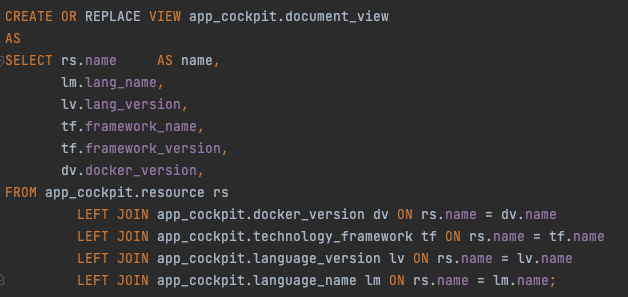
which returns:

The main database view, here called document_view, would be the aggregation of multiple sub-views. Each sub-view would only know about its data structures, hence we would achieve the desired single responsibility and encapsulation traits, making the solution more extendible and more maintainable. Even if something would be changed within one of the sub-views, it would not affect the aggregated view or other sub-views.
As previously mentioned, since we use Spring Data JPA extensively, the database view would be reflected in the code as a JPA entity which would allow us also to use the Criteria API to build a generic query on top of that main view and utilize the built-in PostgreSQL functions, that would come especially handy when interacting with the JSON objects.
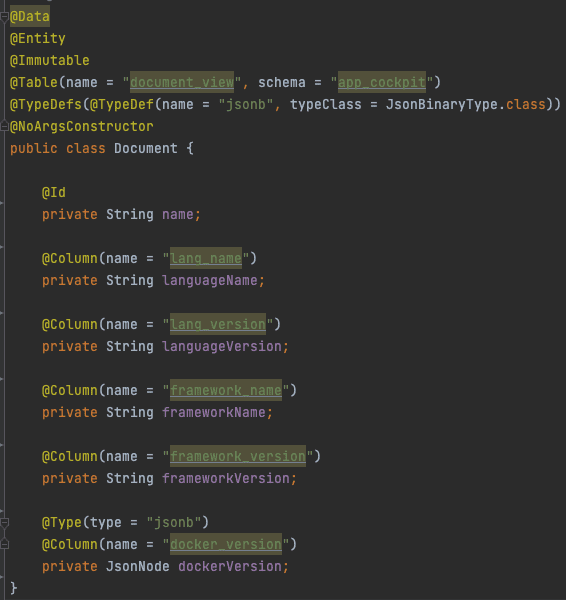
To materialize or not
As the DB views seemed like a good solution, we still needed to answer one more question: whether to materialize them or not. As materialized views would be, obviously, faster to query, but that would not come for free, as we would need to build a mechanism to frequently refresh the materialized views, which would also induce a performance overhead. In the end, as we expect the App Cockpit Search to happen fairly infrequently and we value accuracy over query execution time, we’ve decided to not materialize the views.
The conclusion
Finally, we decided to move forward with the DB view based solution. Although it’s not a silver bullet and requires us to keep an eye on the query performance, as over time the number of sub-views will grow, which might impact the overall search performance, we consider this to be a fair trade-off for the gained extensibility and maintainability of the search functionality.
A story on how OpenAPI helped AUTO1 Tech to move forward faster and in a more structured way.
Analysis of Spring 5.X candidate component index applicability to boost our application startup time

A short trip around the AUTO1 Application Cockpit data model
Machine learning systems are complicated, but good infrastructure can reduce this complexity by...
Building single-page applications
