
Application Cockpit Architecture Overview

Hello fellow concerned developers, or, if you are not yet concerned, while it is not the crux of today’s entry, I hope that by the end of it, you might get interested in becoming one and/or find out how you could do that on your own and what it actually means for us. Still, the focal point of this post is to fill you in on the architecture of Application Cockpit (or “App Cockpit”, as we call it in private), the newest tool AUTO1 has brought in for its concerned developers.
The “why”
However, before dwelling on the “how” too much, let us pay homage to propriety and start with the ‘why’ of the whole matter. The main reason for the emergence of the Cockpit stems from the plethora of tools AUTO1 has adopted to help us trace, measure and monitor our services, not to mention alerting us when things go south. This opulence often means that if you are looking for a specific bit of information, whatever the reason, chances are the data is there somewhere, but you need to make a significant effort finding out where to look for it first.

Once you have figured it out, more often than not, you are invited to dance your way around Kibana, GitHub and Grafana, correlating your findings, perhaps with a touch of Consul and AWS Event Log to help you along the way, sprinkled with a Chronograph query here and there to spice things up. Neither is it fast, nor easy, nor pretty. What’s worse, we have noticed, that as our ecosystem grows, it gradually becomes harder to know what to look for and where to find it and the learning curve for new hires has started growing ever steeper.
…. and the “what”
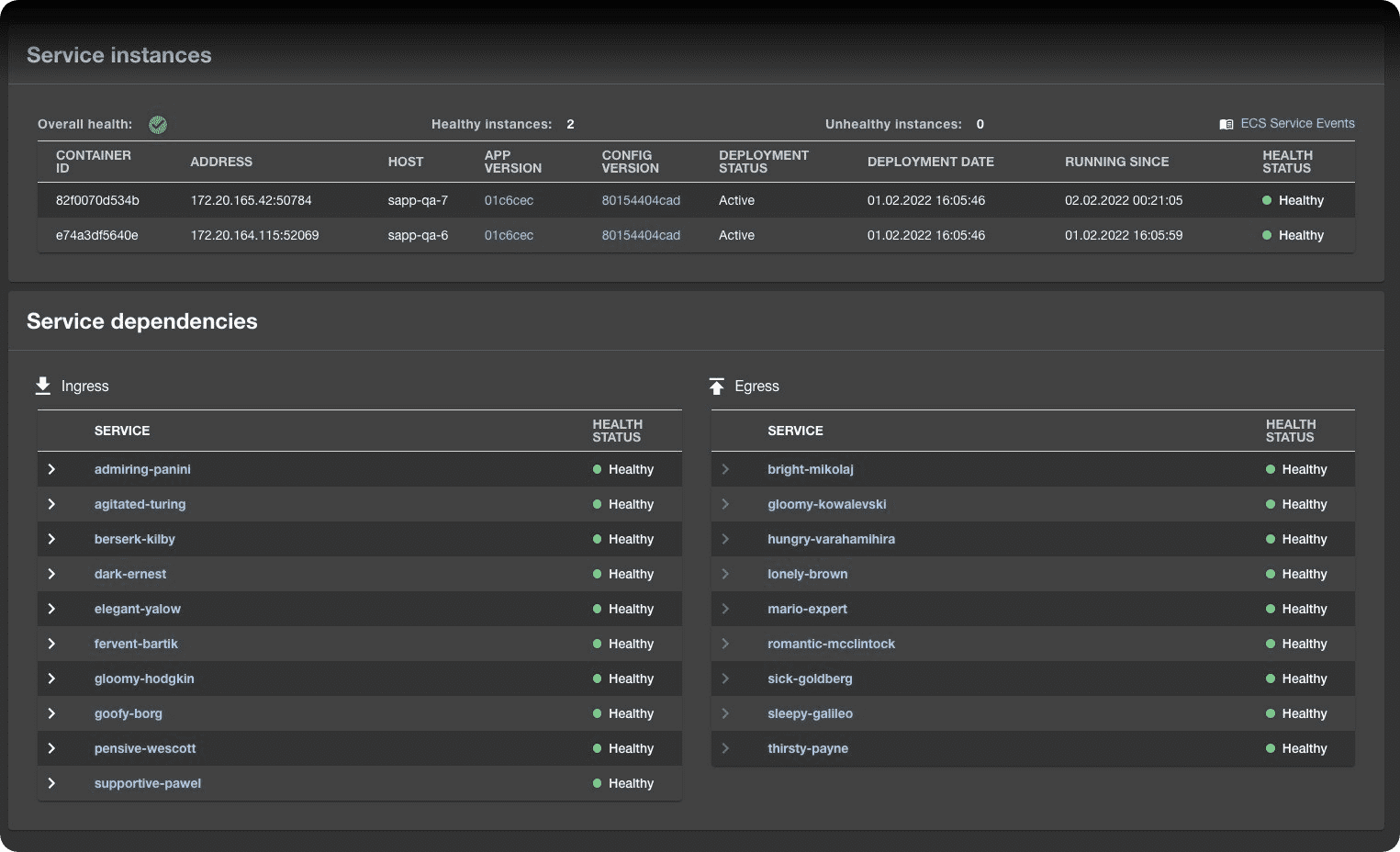
Enter the App Cockpit. In short, the Cockpit is meant as THE tool which lets concerned developers quickly find their bearings and gather relevant information pertaining to a particular service running in our ecosystem. Being concerned, actually, for us means that you care about your services and the ecosystem as a whole and you want to keep your applications in tip-top shape as well as you feel responsible for troubleshooting them when needed.
Keeping that in mind, we’ve designed the App Cockpit to be the first place you check when you want to find out who owns the service, what other services or resources it relies on, is it healthy or not and what its main software dependencies are. It is also meant to be the place you visit first when a service starts misbehaving to be presented with quick troubleshooting aids, or, if you are the owner, to perhaps bask in glory when everything runs smoothly.

To achieve all that, the Cockpit needs to pull data from multiple sources, aggregate it and present it in a comfortable and meaningful manner to the users, not to mention being fast and efficient about it, which leads us to the heart of the matter - the architecture of App Cockpit.
Finally, the “how”….
When designing App Cockpit, we were striving for what probably every software engineer worth his hide can recite even when woken up at 4 am in the morning - we wanted the architecture to be “open and easily extensible, yet simple and robust at the same time", preferably allowing polyglot extensions to let every team in the company contribute and share with others if they came up with a cool feature. In order to achieve this, we have split the Cockpit into 5 logical components distributed in 3 different layers, as depicted below, with the descriptions to follow.
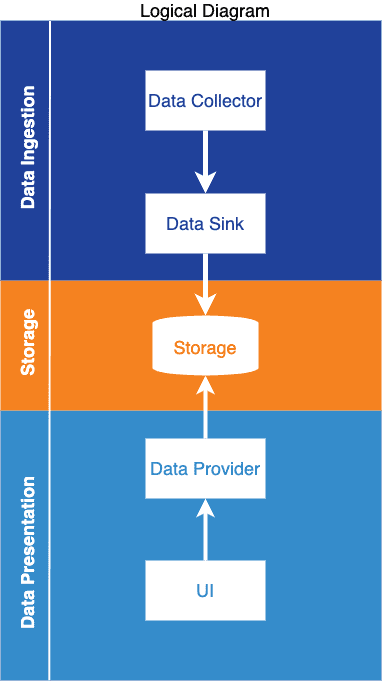
-
Data Collector - the component responsible for fetching data from multiple external sources, parsing, aggregating, transforming and sending it on its way to the data sink with a tiny stretch it might be called the ETL of App Cockpit
-
Data Sink - a simplistic component with a one-track mind, whose only job is to receive data in a well-defined format from the Collector, occasionally perform some simple and generic operations on it (like basic validation and parent id resolution) and persisting it in the data storage
-
Data Storage - a simple storage that holds the current snapshot of App Cockpit data
-
Data Provider (aka Backend For Frontend) - exposes an interface to serve everything our UI needs, both serving the data “as-is” from the storage as well as applying some additional logic to further aggregate and transform it for special purposes
-
UI - yer plain old Front-end - by design contains no logic, it only displays the data as provided
Sweet, but how about a model?
The specifics of the model run outside of our scope, however, getting it wrong could severely hobble the architecture, so it is a story in and of itself, which will have to wait its turn to be told in another blog entry. For our purposes, we will only briefly touch upon it, mainly to establish the domain.
Truth be told, App Cockpit is pretty much a simpleton, since its world consists of only two kinds of things: Readings and Resources and everything it does revolves around the pair.
Accordingly, a Reading is a piece of data that describes a Resource in some way, e.g. a metric value, service name, owning team, the version of Docker image it currently runs etc.
In complement, a Resource is a concrete entity for which Readings can be collected and then served; it can be a physical entity, e.g. an instance of a service or a logical one (e.g. a definition of a service, e.g. “authentication-service”, a software dependency e.g. ‘log4j”, etc). In addition, Resources can form hierarchies, since they support a parent-children relationship.
Given all the above, the main purpose of the App Cockpit is to collect Readings for tracked Resources and present them to the users.
Getting physical.
Having established all the basics, we can now shift our focus to the physical application of the architecture. We will go over logical components one by one and discuss how we have decided to implement it, to finally sum it all up with a full diagram illustrating the complete solution.
UI - we have chosen to implement it using a customized version of Backstage app, built using React JS and available at backstage.io. Since it provides many handy features readily out of the box, it has greatly streamlined the UI development process. Provides a web interface for the users, communicates with Data Provider over HTTP via REST endpoints.
Data Provider - a simple, easily scalable service built in Java using Spring Boot, exposes REST endpoints for UI while fetching data from the datasource over JDBC; Apart from serving Readings and Resources it also has a concept of “calculations”, which come into play when returning plain entities is not enough to present the user with the desired data. Calculations encapsulate any form of additional aggregation, correlation and transformation logic that is performed on the data in order to enable the UI to present more complex views without placing actual logic in the UI itself.
Data Storage - nothing fancy there, while we have briefly considered using a temporal db, we have decided to fall back to plain old PostgreSQL, since the Cockpit is operating on relational data; the decision has paid off, though, since we were able to leverage the built-in JSONB type to store heterogeneous Reading data in a single column. It is a simple, yet powerful mechanism, which makes the system extremely pluggable. Since a Reading is actually a free-form JSON object, all throughout the ecosystem, the only components that need to know its exact model are the Collector implementation that is going to publish it and the actual UI component that is going to display it. Every other piece of the system can be safely kept in the dark and will be more than happy about it.
Data Sink - implemented as a simple lambda function, it has a well-defined job to do; it listens to SNS (AWS' messaging product) events published by the Collectors to its proprietary topic, extracts the payloads, performs simple validation logic and persists them in the storage. In addition, it is also responsible for properly resolving parent Resources for incoming children. This piece of logic would fit in the Collectors as well, however since we have decided to make them stateless, it has inevitably found its way to the Data Sink.
Data Collector - it is the only component for which the logical diagram differs from the physical one, albeit by design. This stems from the fact that the Collector has been meant as the main extension point that other teams, possibly using disparate stacks, can easily plug into when adding new features. By all means, a Collector, as previously stated, is any component that fetches data from an arbitrary source, transforms it into Resources and/or Readings and pushes it to the Data Sink SNS topic.
In consequence, when you want to start collecting a new type of data or start collecting it from a different source, you have two options - either add your implementation in one of already existing collector services, or write your own new one, and the only requirement we superimpose on you is that when you publish to the Data Sink, you follow the format we have specified. At the time this post is being written, we have 3 distinct Data Collector implementations:
-
Main Collector - a general-purpose collector, written in Java and providing data for cross-platform features, e.g.:
-
service ownership
-
incidents
-
Docker images used and their vulnerabilities
-
service health and deployments
-
currently running instances
-
code insights (quality, PRs, contributors etc)
-
-
Java Collector - yet another service written in Java, as the name suggests it collects data strictly related to services written in Java, e.g.:
-
runtime information like JVM and GC being used
-
selective list of JVM parameters passed to the instances
-
egress dependencies for Java services (in this context, the upstream services)
-
-
PHP/Golang collector - the first contribution coming from outside the original App Cockpit team, written in Golang, it is going to provision data for PHP and Golang services, e.g.:
-
egress dependencies
-
vulnerabilities
-
possibly many more to come
-
With a picture being worth a thousand words, let’s have a look at a diagram that gathers all of this in one place:
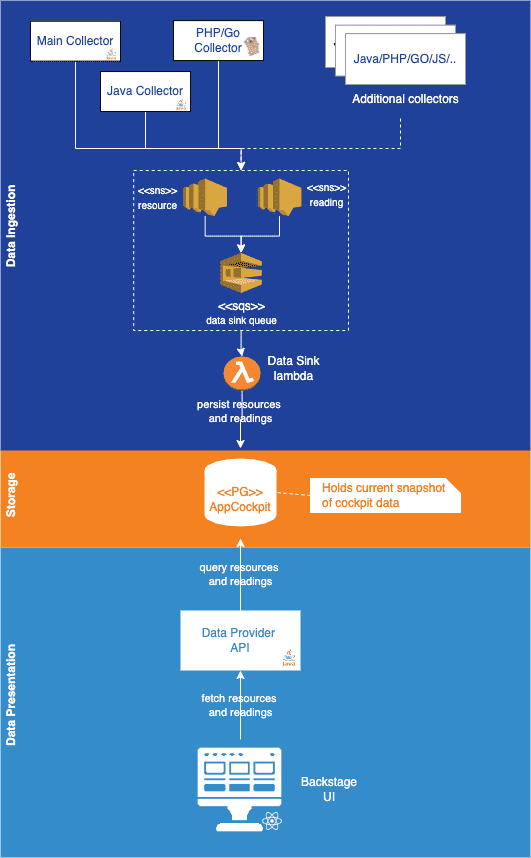
Obviously, the actual process of data collection, as it is currently implemented, is a whole story in and of itself, deserving yet another dedicated blog post, especially since we have elected to make all the collectors stateless, which had its numerous consequences and challenges so keep your eye out for the next entry which is bound to come shortly.
Closing words and … we will be back
Having said, or rather written all the above, we sincerely hope that we have managed to pique your interest. Not only in our solution but also in actually getting “concerned” about your ecosystem, because it does not necessarily have to be boring, especially when you have the right tools to make your life easier. On top of that, you can have your fun building the actual tools, deftly combining business with pleasure for a change of the usual pace.
As hinted numerous times, this is only the preliminary article, meant to lay the groundwork for future additions exploring individual pieces in more depth… We are already looking forward to writing those, so keep your eye out!
A short review of the new Pattern property in net/http.Request
A short trip around the AUTO1 Application Cockpit data model
What I present today is how to use police techniques and their mindset to detect and solve bugs in...
