
Improving our CI/CD system performance with storage migration
Improving our CI/CD system performance with storage migration
In order to scale up our CI/CD build platform running with Jenkins[1], we used to leverage the AWS Elastic FileSystem, also known as EFS, to provide a network filesystem that can be mounted across one or more VM instances.
This deployment setup works well with a containerised workload as the orchestrator can schedule the container or virtually any node on the cluster, therefore we need to make sure the storage is available for every instance where the build platform will be deployed. We accomplished this by simply attaching the EFS storage in all nodes on the cluster, thus allowing the container to be rescheduled in any instance at any time.
However, we started to face some challenges with the increase of new services and the introduction of features such as Jenkins Pipeline and Multibranch Pipelines. We noticed that the system build queue was growing bigger over time, as our build system was taking longer to process the services pipelines, with a direct impact on the development time and life cycle.
In our investigation and analysis we identified the storage file system as one of the biggest contributors to the performance of the Jenkins Master node. We tested and decided to migrate the Jenkins filesystem to another storage type - AWS Elastic Block Store service, also known as EBS, that provided better performance in our tests compared to the EFS file system.
The Jenkins Home directory will often be composed of lots of small to medium size files, which can be troublesome when operating in a network file system due to the overhead required to send the file operations over the network. Moving Jenkins to a faster storage system can lead to a great performance impact on the overall build platform.
The downside of running the platform on AWS EBS is that we degraded the high availability of the platform as EBS is limited to a single Availability Zone (actually, one of the reasons why the storage is faster), leading to an adjustment to the service deployment, ensuring it’s deployed on the same AWS availability zone and introducing new plugins that will integrate the container system with EBS. The new adjustments also introduce more complexity to the infrastructure. Nevertheless, we decided that improving the performance of the system will bring more value to the development side and consequently could have a positive impact on the business.
Performance improvements with EBS
Most of the performance gain is bound to the Jenkins Master itself, as only the master was using the EFS storage and the Jenkins Build Nodes were already using EBS or instance local storage. Nevertheless, there could still be improvements as the Jenkins Master was responding faster even when when communicating with the build nodes.
After the migration to EBS we started to see an improvement on the Jenkins Master Build Queue. In the following graph, we can see the number of builds queued to be processed. The bigger the queue, the longer the waiting time for the new jobs to start the services pipelines build and deployments.
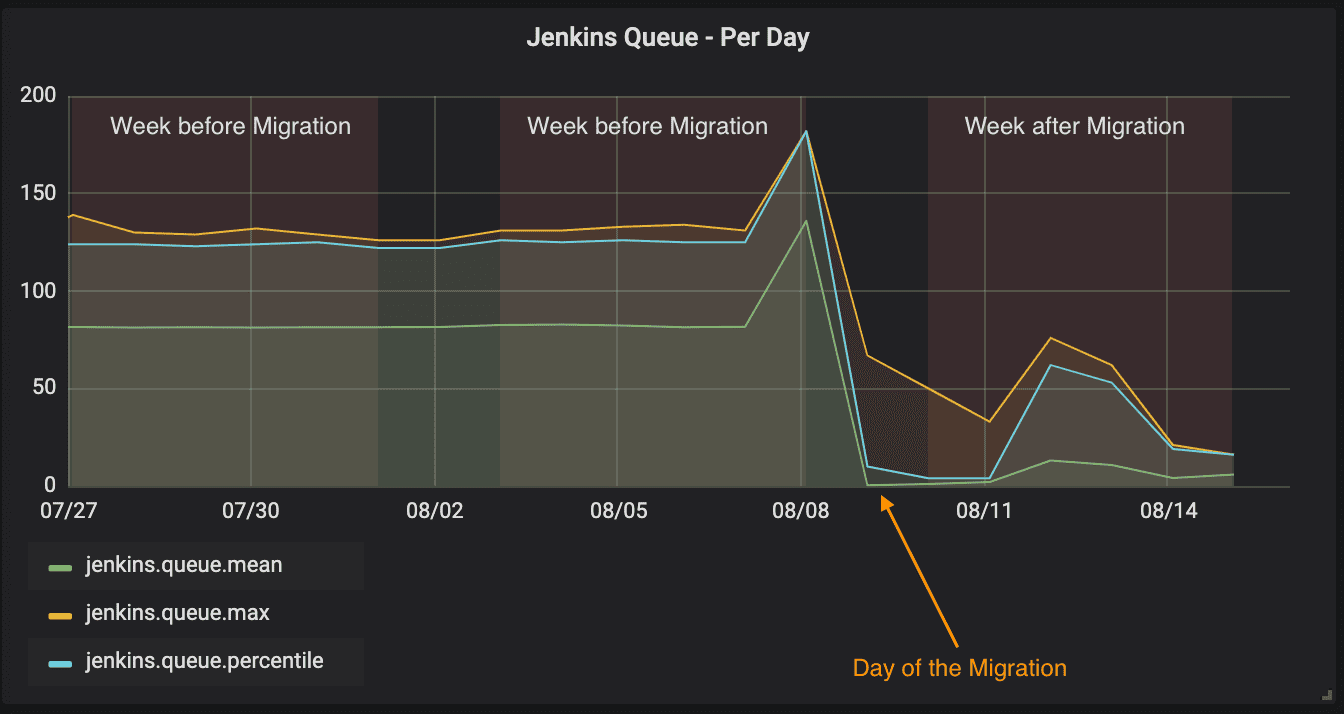
The migration started on the 9th of August and finished on the 11th of August, with a noticeable decrease of builds in the queue. The graph is less stable after the migration because the queue was running faster for some builds, depending on the type and project repository size. Additionally, this behavior happens due to the fact that most of the multibranch pipeline projects are scheduled to run every minute and usually start at the top of the minute, while with the performance improvements the build was finished faster and did not postpone or queue the consecutives runs, on the next minute.
Jenkins Master Multibranch Pipeline running time
One of the most significant improvements we can see is the time spent by Jenkins evaluating a multibranch pipeline job [1].
Using the EFS storage we noticed in some cases it will take around 5 minutes to finish a MultibranchPipeline scanning process[1]. as shown on the image below:

On the other hand, with the EBS storage, the build dropped to 4 seconds as shown on the image below:

The above is just a sample from a single project and does not represent the state of all the builds. In order to evaluate the performance across all builds, we extracted the build logs from two days (Monday and Tuesday) of the week before and after the migration took place. After calculating simple statistical functions on our data we could see a more general picture of the performance improvements as the following:
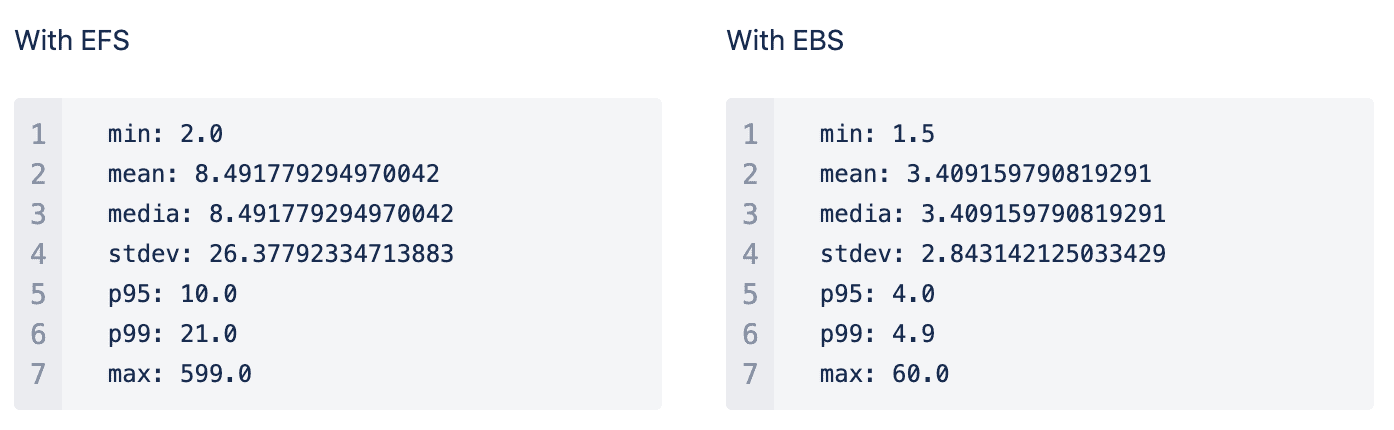
According to these metrics we are performing on average 3x faster than the previous implementation. One of the most significant improvements is the standard deviation metrics. In the previous implementation the standard deviation was around 30 seconds, which means on average the majority of the builds took between 8 and 30 seconds to be scheduled. With the new implementation most of the builds started between 3 and 5 seconds on average.
Another metric that is worth taking a look at is p95 (i.e: 95th percentile) and p99 (i.e: 99th percentile). With EFS we performed 99% of the build scheduling in at least 21 seconds, with the EBS the p99 indicator is close to 5 seconds, with a 4.2 times faster result on average for most of the builds.
Summary
After the migration to the storage system we could immediately see performance gain on the build system, which can lead to a greater impact for the entire engineering department, especially inbetween the times developers push the code and having the changes tested and built into the infrastructure.
Another big improvement was the Jenkins UI navigation, specifically the time that takes to render the build's outputs - while using a much faster navigation developers could be faster in spotting any build issues and increasing the overall user experience.
We calculated a simple estimation and we expected an impact of 2 hours on engineering - based on the time Jenkins takes to process the pipeline and start the builds, and the time it takes to scan a multibranch pipeline. This estimation does not account for indirect performance gains such as navigating into Jenkins UI, like when waiting on Jenkins to render the build’s output.
References
[1] Multibranch Pipeline job is processed by cloning down the GitHub repository, scanning on the branches looking for a Jenkinsfile into the project root directory and creating or starting a build on the given branch when a new branch is created or the branch received any git changes.
This article describes our journey to adopt KICS terraform scanner into our toolset. We will go...
How to setup monitoring tools on TV screens using Raspberry Pi

Sometimes elastalert returns unexpected results, sometimes it does not alert although one would...
