
Serving JSON (almost) directly from database

RESTful API’s are ruling the industry nowadays. They are very often associated with an extremely popular data format - JSON. It is so popular that database creators decided to implement it directly in the database engines. All modern databases offer JSON processing capabilities. Let’s have a look and see how can we make use of them to improve our application’s performance.
JPA or JDBC?
The typical choice for a Java application is to use JPA as the persistence layer abstraction. It became the de-facto standard for a reason - it offers great flexibility and ease of use. Unfortunately it doesn't come without a price since we have to pay with degraded performance.
It is a widely known fact that ORM’s impact performance, compared to pure JDBC. On the other hand, relatively few are willing to use plain JDBC, considering the amount of additional work it requires.
Let me demonstrate how to use JDBC to leverage the performance, with the help of modern Postgres features.
Demo time
I have prepared a demo application running on Spring Boot which exposes example data from the northwind database. The data are exposed in three different ways.
The baseline version simply exposes JPA entities:
@GetMapping(path = "/v1/orders/{order_id}",
produces = APPLICATION_JSON_VALUE)
public Order getEntity(@PathVariable("order_id") Integer orderId) {
return orderRepository.findById(orderId).orElseThrow();
}The Order entity aggregates data from numerous database tables: orders, order_details, products, customers, customer_customer_demo and customer_demographics.
You could check the corresponding JPA mapping here.
Thanks to the magic of Spring the entity is being translated into a JSON response:
{
"orderId": 10284,
"employeeId": 4,
"orderDate": "1996-08-19",
"requiredDate": "1996-09-16",
"shippedDate": "1996-08-27",
"shipVia": 1,
"freight": 76.56,
"shipName": "Lehmanns Marktstand",
"shipAddress": "Magazinweg 7",
"shipCity": "Frankfurt a.M.",
"shipRegion": null,
"shipPostalCode": "60528",
"shipCountry": "Germany",
"orderDetails": [
{
"orderId": 10284,
"productId": 27,
"product": {
"productId": 27,
"categoryId": 3,
"supplierId": 11,
"productName": "Schoggi Schokolade",
"discontinued": false,
"quantityPerUnit": "100 - 100 g pieces",
"unitPrice": 43.9,
"unitsInStock": 49,
"unitsOnOrder": 0,
"reorderLevel": 30
},
"unitPrice": 35.1,
"quantity": 15,
"discount": 0.25
},
{...},
{...},
{...}
],
"customer": {
"customerId": "LEHMS",
"companyName": "Lehmanns Marktstand",
"contactName": "Renate Messner",
"contactTitle": "Sales Representative",
"address": "Magazinweg 7",
"city": "Frankfurt a.M.",
"region": null,
"postalCode": "60528",
"country": "Germany",
"phone": "069-0245984",
"fax": "069-0245874",
"customerDesc": [
{
"customerTypeId": "AAAA",
"customerDesc": "First demographic"
},
{...},
{...},
{...}
]
}
}The demo project includes the p6spy library which gives an insight into the queries being issued against database. Turns out that three queries are required to load a particular Order - this means three database round trips.
Of course we can force the ORM to join all the tables and fetch them in one hop, but this seems a not so elegant solution - it pushes the ORM to load duplicated data and the necessity of deduplicating them in-memory. Can we do better?
JDBC to the rescue
JDBC is always a choice if the solution could be expressed via SQL query. Luckily we can create one which matches our case perfectly:
WITH products("productId", "categoryId", "supplierId", "productName", "discontinued", "quantityPerUnit",
"unitPrice", "unitsInStock", "unitsOnOrder", "reorderLevel") AS
(SELECT p.product_id,
p.category_id,
p.supplier_id,
p.product_name,
p.discontinued::boolean,
p.quantity_per_unit,
p.unit_price,
p.units_in_stock,
p.units_on_order,
p.reorder_level
FROM products p),
orderDetails("orderId", "productId", "product", "unitPrice", "quantity", "discount") AS
(SELECT d.order_id,
d.product_id,
(SELECT to_json(p) FROM products p WHERE p."productId" = d.product_id),
d.unit_price,
d.quantity,
d.discount
FROM order_details d),
demographics("customerId", "customerTypeId", "customerDesc") AS
(SELECT ccd.customer_id,
ccd.customer_type_id,
cd.customer_desc
FROM customer_demographics cd
JOIN customer_customer_demo ccd on cd.customer_type_id = ccd.customer_type_id),
customers("customerId", "companyName", "contactName", "contactTitle", "address", "city", "region", "postalCode",
"country", "phone", "fax", "customerDesc") AS
(SELECT c.customer_id,
c.company_name,
c.contact_name,
c.contact_title,
c.address,
c.city,
c.region,
c.postal_code,
c.country,
c.phone,
c.fax,
(SELECT to_json(array_agg(to_json(d))) FROM (SELECT "customerTypeId", "customerDesc" FROM demographics WHERE demographics."customerId" = c.customer_id) d)
FROM customers c),
orders("orderId", "employeeId", "orderDate", "requiredDate", "shippedDate", "shipVia", "freight",
"shipName", "shipAddress", "shipCity", "shipRegion", "shipPostalCode", "shipCountry", "orderDetails",
"customer") AS
(SELECT o.order_id,
o.employee_id,
o.order_date,
o.required_date,
o.shipped_date,
o.ship_via,
o.freight,
o.ship_name,
o.ship_address,
o.ship_city,
o.ship_region,
o.ship_postal_code,
o.ship_country,
(SELECT to_json(array_agg(to_json(d))) FROM orderDetails d WHERE d."orderId" = o.order_id),
(SELECT to_json(c) FROM customers c WHERE c."customerId" = o.customer_id)
FROM orders o)
SELECT to_json(orders) AS json_body FROM orders WHERE orders."orderId" = ?The query looks verbose, perhaps a little enigmatic. It is a bit long and therefore it could be overwhelming. However, on a closer look we could notice it isn't so much complicated - there are few idioms which make the query powerful.
The good news is that the query generates the exact same JSON as the JPA endpoint provides - it is possible thanks to Postgres’ excellent support for JSON format.
Our case is not sophisticated though - single to_json function is enough to deal with JSON objects and arrays.
One can notice how the nesting has been realized: how to nest JSON objects and JSON arrays, e.g. the orderDetails or the customer into order).
The simple idiom (accordingly to_json(...) or to_json(array_agg(to_json(...)))) does the job.
The database query could be adapted according to the caller needs - the response can be shrinked, making the query simpler and - most probably - even more effective.
Worth noticing is that the join table customer_customer_demo has been mitigated in the end result, just like the JPA version does by using @ManyToMany.
The query is flexible enough to substitute all JPA features we need.
I want also emphasize the fact of CTE’s being used to decompose the query into logical parts. Personally I find it elegant because it is easy on the eyes and it “scales” - meaning while our case gets more complicated (JSON aggregates more data, becomes deeply nested) our query gets longer instead of getting deeper. If the query grows too long we can simplify it by extracting some it’s parts as database views.
The CTE has one more advantage here: it gives a control over the keys visible in end resulting JSON (order_id becomes orderId).
So we have a nice query which allows us to fetch required data in one hop in a format ready to be consumed by our clients. This means no adjustments are required, therefore the Java implementation can be that easy:
@SneakyThrows
@GetMapping(path = "/v2/orders/{order_id}",
produces = APPLICATION_JSON_VALUE)
public String getRawBodyFromDatabase(
@PathVariable("order_id") Integer orderId) {
return jdbcTemplate.query(JSON_QUERY, (ResultSet rs) -> {
rs.next();
return rs.getString(1);
}, orderId);
}We didn’t use plain JDBC here but a JdbcTemplate which has a negligible overhead and it simplifies our code.
Of course we could achieve similar results using plain JDBC (e.g. by using PreparedStatement directly) - without the use of Spring.
Even then the necessity of extracting only a single field from the result set makes the solution less coarse than using JDBC in a usual way
(in our case it would require managing at least three result sets).
All the complexity has been moved down into the query.
But I need a POJO!
Some folks could argue “I don’t want the JSON to be directly returned - I definitely need the POJO to make some processing over it”. That's an absolutely fair statement! We can satisfy this requirement as well.
Let’s point it one more time: our query produces the exact same JSON as the Order JPA entity has been translated into.
This means we can use the resulting JSON and unmarshall it into an object of class Order.
Of course the object won’t be tracked by the JPA whatsoever but we don’t need these capabilities - remember: we are serving persisted data and not mutating them.
@SneakyThrows
@GetMapping(path = "/v3/orders/{order_id}",
produces = APPLICATION_JSON_VALUE)
public Order getEntityNotUsingJpa(@PathVariable("order_id") Integer orderId) {
return jdbcTemplate.query(JSON_QUERY, (ResultSet rs) -> {
rs.next();
return unmarshall(rs.getString(1), Order.class);
}, orderId);
}
@SneakyThrows
private <T> T unmarshall(String json_body, Class<T> clazz) {
return objectMapper.readValue(json_body, clazz);
}This version is very similar to V2 but it introduces an additional step of unmarshalling. It is also a great verification step which makes us sure the V1 and V2 results are identical.
Measure, measure, measure
So how are all the solutions performing? We suspect the V2 version to be faster than the competitors. We are also unsure about the V3 which requires additional unmarshalling phase - could it impact the performance badly?
The demo project includes a JMeter configuration and a bash script which verifies the configurations. The benchmark is always run against a fresh setup (db + app). The app is running on java 11 with EpsilonGC turned on - this allows us to verify memory consumption of each solution.
The requests are run in strictly defined sequence, fetching the orders one by one. There’s a prewarming phase which issues 100 requests and then a profiling phase with 20k of requests.
I have run the benchmark several times on a Macbook Pro 2018, the results are similar on each run. Here’s a summary of the most recent run:
- V1 took 1 minute and 25 seconds to complete the benchmark, the docker container ended up using 1762 MB (1.641 GiB) of memory.
- V2 took 53 seconds to complete the benchmark, the docker container ended up using 1710 MB (1.593 GiB) of memory
- V3 took exactly 1 minute to complete the benchmark, the docker container ended up using 1758 MB (1.638 GiB) of memory
We can see the V2 outperforming the V1 by 32 seconds - that’s 37% improvement.

We can notice also a lower memory consumption on the V2 - it used 52 MB (49 MiB) less memory than V1 (noted the initial app’s memory usage which is 785 MB):


Worth noticing: the V2 version does not leverage Hibernate at all therefore we could minimize the memory footprint even more by excluding the JPA dependencies.
Let’s have a look at response times:

Once again we are able to notice improved throughput as well as lower latency.
The plot confirms that as well (cropped for brevity):
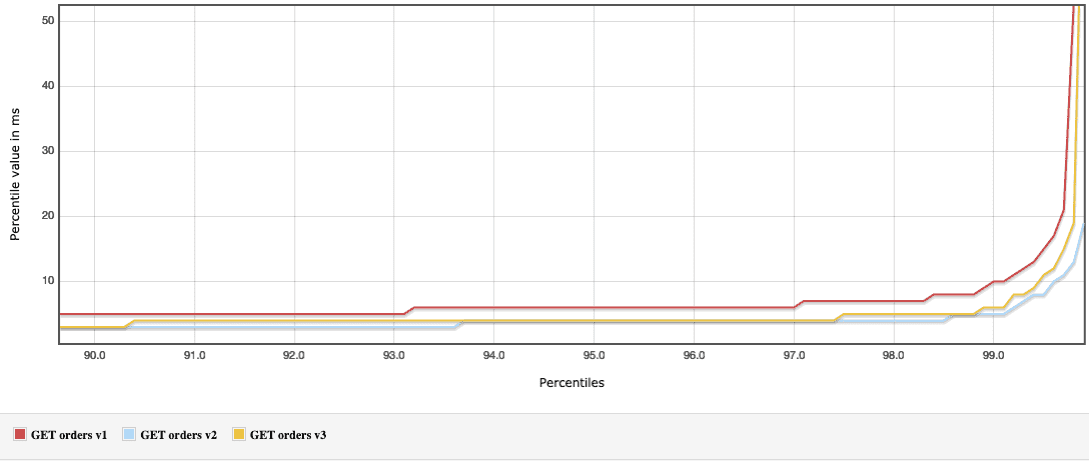
Personally I am very well satisfied with the V3 results - the memory consumption being at the same level as the JPA it still offers satisfying performance, nearly as good as the V1. It proves that the unmarshalling does not impact the performance as badly as we might expect.
I really encourage readers try running the benchmark and share their own results!
Postgres 12 exclusive
Last words about the database: the results are reproducible currently only on Postgres 12, due to recent improvements in Common Table Expressions.
I have had a run on Postgres 11 and the V2’s performance was… horrible - I had to shorten the benchmark 10 times to make it finish in a reasonable time. Here are the results I got:
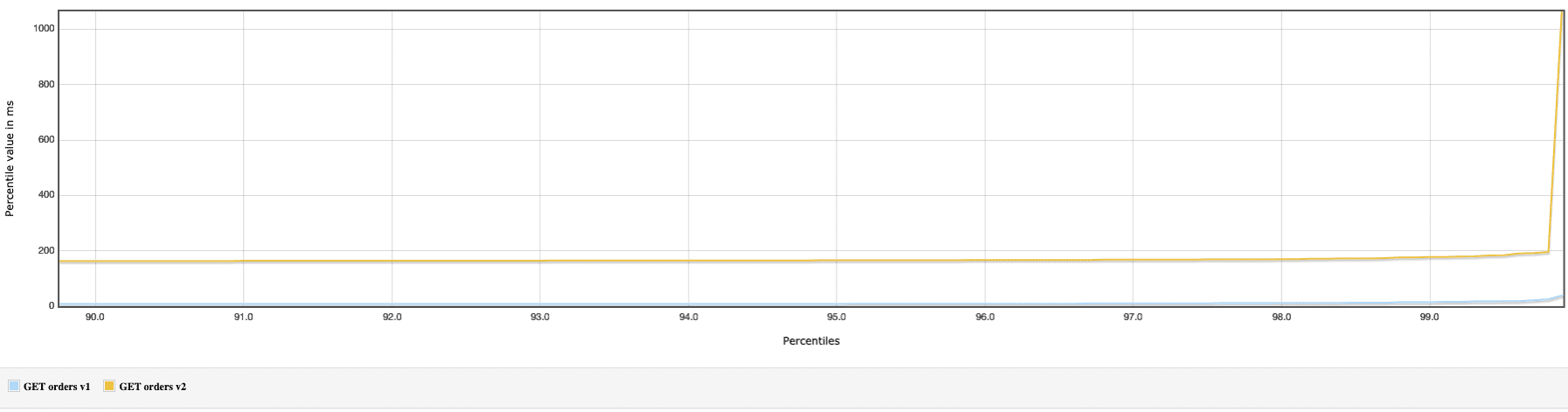
You can give it a try - the demo app is prepared to allow a quick switch to Postgres 11.
Summary
The query we have prepared enables fine control over the data being fetched from database.
We are no longer restricted to tabular data - we could easily fetch complex data graphs, even manipulate them to match the desired format. We did it keeping the solution maintainable and very effective in terms of throughput.
It is still unknown to me what is the main source of latency in the JPA version: either is it the additional round trips or the internals of Hibernate. I see the topic interesting to explore. Perhaps some day we’ll get an ORM which is able to load entity graphs using a single query. Any Hibernate devs reading here?
Improved Common Table Expressions in recent release of Postgres

Improved Common Table Expressions in recent release of Postgres