
How We Implement Feature Requests at AUTO1
How We Implement Feature Requests at AUTO1
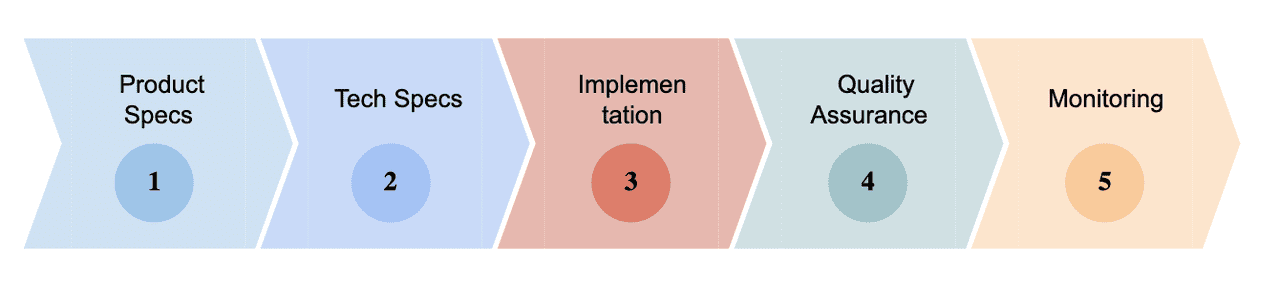
In this blog post I want to emphasize how important the process of exceptional software delivery is. I’m going through all the steps used by AUTO1 to achieve the best possible implementation in software development. All in all, there are 5 steps that require a clean and effective implementation:
- Product Specs
- Tech Specs
- Implementation
- Quality Assurance
- Monitoring
In the following I would like to go into detail about these steps.
1. Product Specs
The most valuable feature implementation does not help if you have a bad user experience. This is why the product managers at AUTO1 work closely with the design team to build great product specifications and UIs to let the users handle their work with the application easily.
The product specs are usually divided into stories to simplify the work on them for designers, as well as software engineers. Once this is done, the software engineers work their way up from specifications and UI to database schemas, requests and responses, etc. in the tech specs.
2. Tech Specs
One vital process for building new features at AUTO1 is the concept of creating Tech Specs. Tech Specs stands for Technical Specifications, and is basically a design document that represents the bits and pieces of a new feature implementation. At AUTO1, we have over 600 microservices that are handling various different tasks. So to provide exceptional and error-proof work, we create a sort of contract between developers within a team that are aware of how the technical implementation has to be done. The Tech Specs generally include the following important information:
- An agreement of Requests/Responses between FE and BE engineers so that FE/BE can work autonomously
- Api Relationships between services that provide specific data that is needed for the implementation
- Architectural diagrams of the Api flows between services
- Database schemas
- Finding consent between other teams that are affected by the changes
With that said, the Tech Specs provide very helpful instructions to put all engineers on the same implementation ideas so the work can be accomplished in a straight-forward manner.
3. Implementation - a few key takeaways
In the following I would like to go into detail about a few key takeaways for one of our implementations in the production domain.
Tech Decision 1: Data duplication to provide a fast search
One of the key points of a new feature implementation in the Production domain was to provide a list of specific data regarding cars that have to be refurbished. This list should also include a search on the top to look up cars by specific values like the VIN (Vehicle Identification Number), stock number, and refurbishment number. In order to get the appropriate data we have to send request to multiple services. There are actually two ways to fetch the cars by the given filters:
- Use the Aggregator Pattern and request two api endpoints to combine the data afterwards and list the cars.
- Import the data into the database of the new service and simply query it.
Let's have a deeper look at these two methods....
Method 1 - The Aggregator Pattern
The Aggregator Pattern is usually a standalone microservice. It offers a uniform API that a client can use to access data from different microservices.
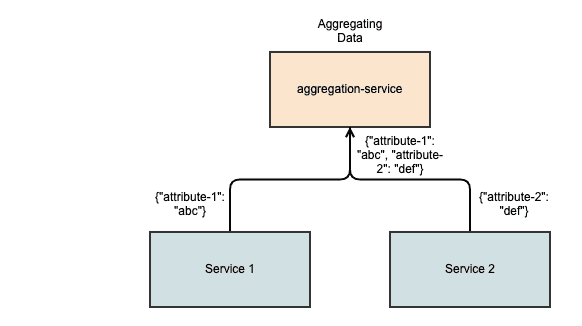
This composite service is utilized when we need to prepare the result data produced from the outputs of several microservices. The aggregator pattern is designed to combine data from several endpoints and provide it as a single endpoint to the client. If necessary, it can also cache that data according to predetermined criteria or rules. You can read more about this pattern here: https://www.edureka.co/blog/microservices-design-patterns
So to sum up, we can simply execute two or more api requests to separate services and accumulate the data we need to show the results in the list. This sounds good, except for one drawback: Performance! It is at the expense of performance. One more way to enhance this behavior is by using asynchronous api requests, which basically execute these multiple api requests in parallel. However, it does not provide the best performance (depending on the use-case, it was not an option for us).
Method 2 - Importing the data into the microservice
Since the data like VIN, stock number, etc. will not change in the future, importing fixed data to the service database sounds very suitable. So the key message here is: don't rely on sending synchronous queries to obtain data that was previously controlled by another microservice if your primary microservice requires it. Instead, use consistency to duplicate or propagate that data (just the properties you require) into the other service's database.
The only data that changes over the course of a refurbishment is the state. For syncing the refurbishment state, we used asynchronous messaging. Every time the initial state of a refurbishment is changed, a message will be produced to SQS (Simple Queue Service). From there, we can easily consume that message and change the state in the new microservice.
To provide a fast search, we added an index only to the state field, since too many composite indexes can have degradation on insertion, deletion, and updating performance. The Data Manipulation Language statement has to modify the table data and the indexed data too, which might decrease the performance depending on the amount of data. We have slow query alerts in place, so we get notified when it might be time for an investigation to improve the performance.
Tech Decision 2: Event Sourcing the State Changes
Event sourcing is a way for an event-driven microservice to respond to events in order to carry out its tasks. A higher-level operation is performed by a number of these services interacting with one another in an event-driven architecture based on messaging. The interaction usually consists of a series of messages taken by the various services to handle, for e.g. state changes.
Messaging at AUTO1 works in the following way. Every service that publishes messages must specify the SNS topic to which it intends to deliver those messages. Topics are bound by message type, so if the message type is Refurbishment.State then the topic is named Refurbishment_State. Messages are then routed to the subscribed SQS queues using topics that have been specified. These messages can be consumed by multiple consumers.
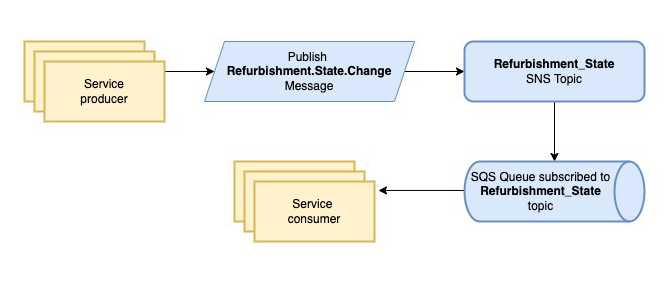
So to keep the state changes updated, we created a Message Listener that listens to state changes and updates the state. A message producer for the state changes was already in place since several other services needed to consume this message as well and make their own updates.
Tech Decision 3: Implementing Feature Flags
Feature flags can be helpful in a variety of situations. It's essential to understand that feature flags can be used to configure a wide range of application components. Some feature flags are used to run specific parts of the application, and some feature flags intentionally prevent that. Additionally, feature flags may be applied to the frontend and/or backend. Enabling or disabling features for individual parts of an application is a common use case.
The strategy we usually apply is to enable features for specific car repair workshops using a feature flag. That way, we can steadily monitor for errors and let the feature evolve so it is ready to be rolled out to all the other car repair workshops as well. For some features, it might be needed to backfill data to pre-existing entities to support the feature in earlier refurbishments.
4. Quality Assurance (QA)
Quality assurance is an essential part of software development and therefore should ideally take place not only at the end, but throughout the development process.
If you want to create good software, you should include software tests in the development process from the very beginning. Here are three reasons for the need of good-quality testing:
-
A high-quality user experience is guaranteed by quality assurance
Software quality issues have an impact on functionality and as a result the user experience. When it comes to developing good software, the user always comes first. Only this ensures that the product is of high quality. -
Quality assurance saves time and money
Those who recognize quality assurance as an essential component of software development from the start save time and money. The later errors are discovered, the longer the development time and the higher the costs. -
More security is provided by quality assurance
Continuous quality assurance throughout the development process ensures that security vulnerabilities are detected and addressed early on.
5. Monitoring
To improve the quality of an application, you need monitoring. Application monitoring helps developers to locate bugs easier and speeds up the development time. If application monitoring is ignored, it could lead to unexpected crashes or poor performance that would cause significant harm to the company. It can enable engineers to gain insights into how their systems will behave.
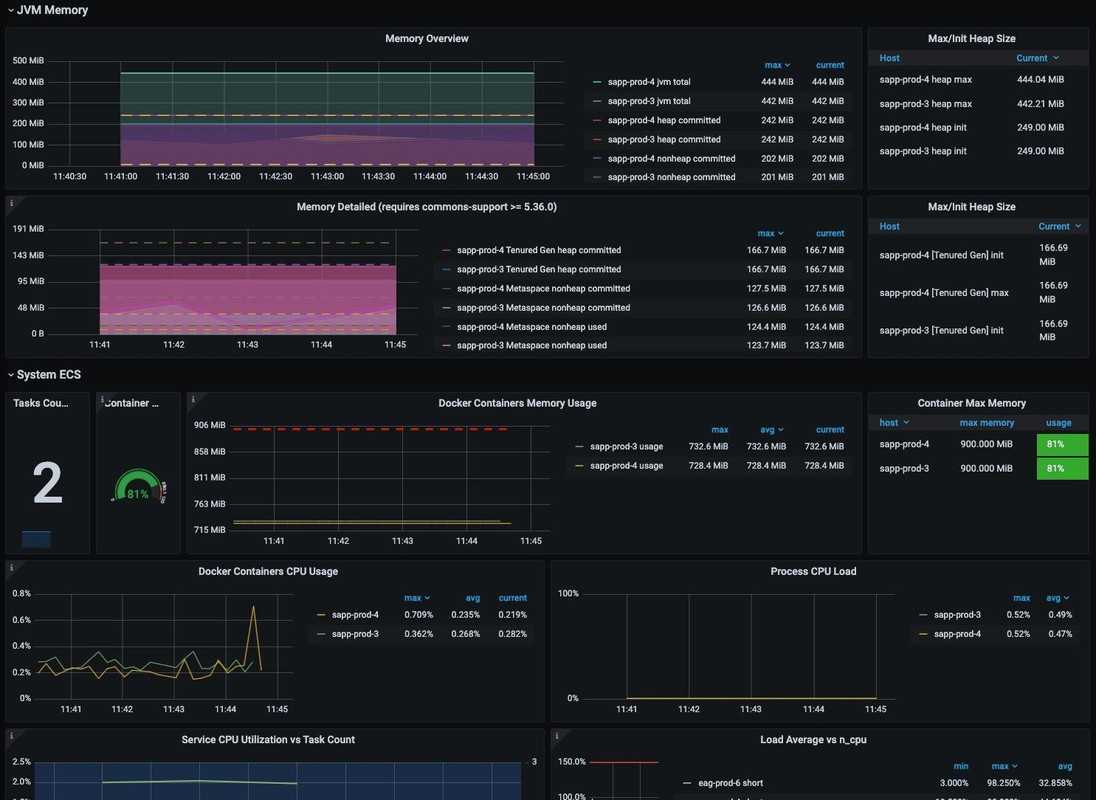
This information enables them to identify issues or flaws while they are still small enough to be handled with relative ease. At AUTO1 every new service has its own Grafana monitoring dashboard to provide several key metrics like:
- JVM Memory usage
- JVM Heap size usage
- ECS Container Memory usage
- Docker Container CPU usage
- Load Averages
- Garbage Collector Metrics
- Cache Metrics
- Thread Pool Metrics
- etc.
Conclusion
Working on a feature implementation is guided by a step-by-step process to provide the best solutions possible on every part of the application.
The key lesson here is that the process is intertwined with the product itself. Because of this, each stage in the development process — from planning to execution — involves stakeholders, product managers, designers and software engineers. You don't have to plan too much in advance. Software engineers can always make up tentative plans as they go, saving them time and also increasing their productivity.
A short review of the new Pattern property in net/http.Request
A short trip around the AUTO1 Application Cockpit data model
What I present today is how to use police techniques and their mindset to detect and solve bugs in...
