
Enter the End to End Testing of Internal Libraries
When a software-based company grows, it creates lots of new code, which means multiple engineers may be facing the same problems across the whole platform. They will usually come up with various solutions to fix it. Some of them might be generic and reusable, while others will be tailored to one’s needs. As it usually happens, the solutions will then be bundled together to create libraries. This is very good, up to a certain point, since over the years, engineers will create them by the dozens and this, in turn, will bring about other hurdles such as:
- how to maintain multiple libraries or prevent buggy code from getting in
- how to release one of them or many at the same time
- how to ensure a smooth process for updating libs for service maintainers
- how to ensure cross-compatibility for all of the libs
This was quite a big pain point for AUTO1 software developers as we have 60+ common libraries that need to work perfectly in 600+ production services across multiple business units and products. One simple mistake, for example, a wrong configuration change leftover after a debug session can end up in disaster.
Enabling protection against direct commits for main branches will address the first hurdle - only pull requests with double approvals and tested by CI can be merged.
The next 2 issues are more about ease of usability for the developers, as they might be reluctant to upgrade their service if the process is troublesome. So, in the best-case scenario, our end-user should periodically update only a single property. In addition, our common library developers need to be able to easily publish their changes.
The solution to it was the release trains, usually known as BOMs or for AUTO1 developers, service-commons-dependencies. After successful implementation, you will just need to trigger CI build to get the newly released version, which in turn can be pasted into a pom/gradle file. So, right now everything looks good, but can we be 100% sure that our changes are going to work? Perhaps there is a very small bug in a messaging lib or we will lose tracing for incidents. That’s unacceptable. So let’s ensure that will never happen by introducing automatic real use case testing.
In our approach, we thought most of the problems could be revealed by running extensive integration testing. The test harness probably catches all bugs in our codebase and simply fails when needed preventing the release of a buggy version.
But no matter what you do or how extensive your tests are, you are never going to be able to perfectly mock the production environment.
Enter the End to End testing of newly released service-commons-dependencies, more commonly known in AUTO1 from here on out, “E2E testing”.
To get it done, we need CI pipelines that will automatically test our new versions of release trains that are triggered either manually or automatically every week. All tests need to be as close to the real-world scenarios as possible. A practical solution is to create a new service that will include all of the most popular use cases of the aforementioned libs. Then we need to deploy it to all of our environments - as previously mentioned there is always something different between local, QA, and production environments, so we need to cover them all. The tests must be the same for all environments. But the trigger may differ - for example, we are using our test environments to prepare new releases for production.
The following diagram illustrates the basic principle of how it should work:
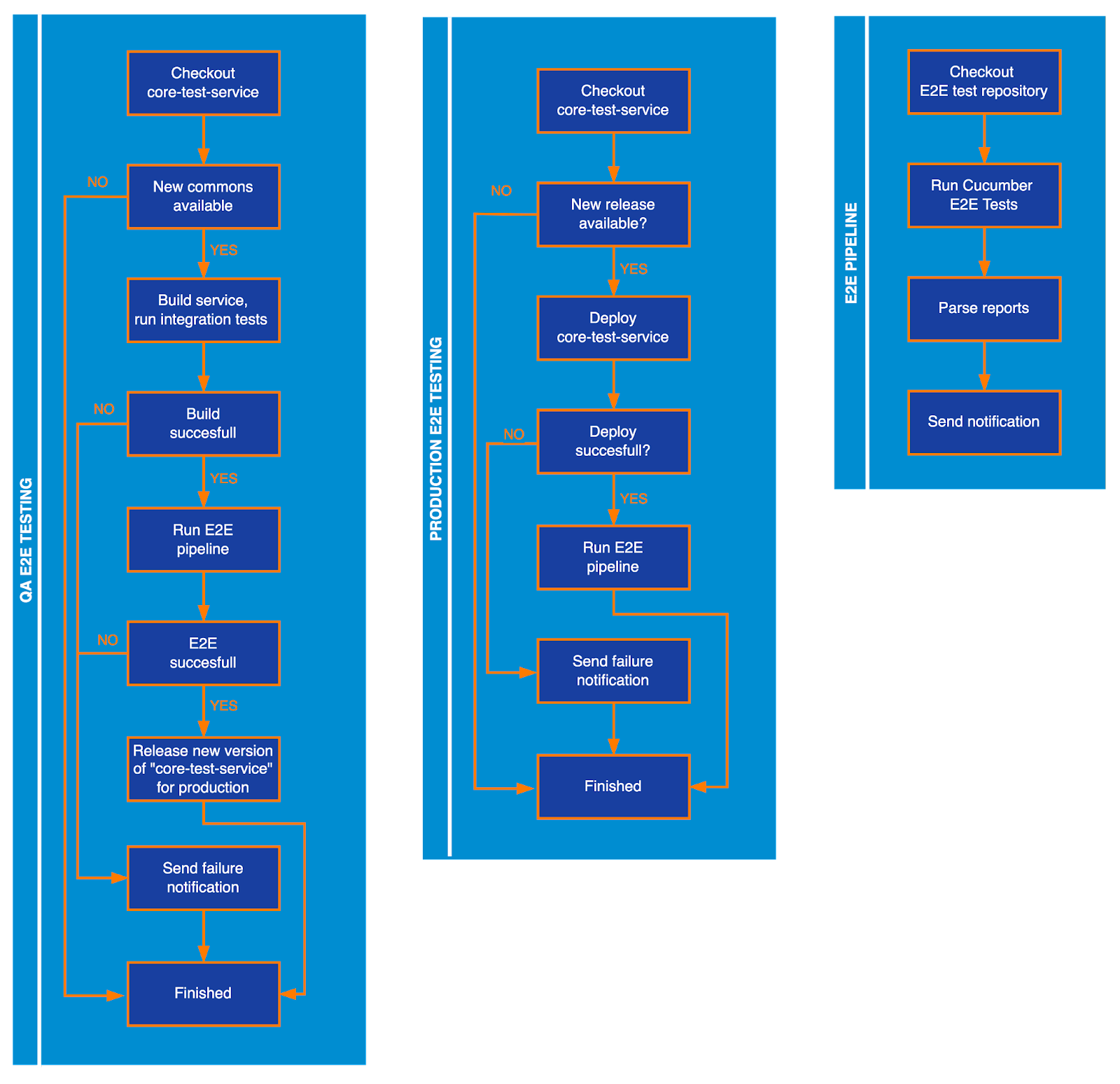
In our implementation, we chose to use Jenkins with JobDSL pipelines and Groovy for scripting. The first stage of the E2E process is checking whether a new version of service-commons-dependencies exists by using the maven versions plugin:
mvn -U versions:update-property -Dproperty='service-commons-dependencies.version'To check for any changes:
def hasChanges = sh(returnStatus: true, script: "git diff --exit-code")If nothing new was found let’s just abort the pipeline and wait for another CRON or manual trigger. In case a new release was found, we need to build it, deploy it, and run E2E tests. If there are no failures the pipeline will create a new core-test-service release. For those cases, we are using parameterized jobs, for example, to trigger the E2E tests we can use the following commands:
build(job: 'java/core-svc/core_test_end_to_end_test', parameters: [booleanParam(name: 'SEND_SLACK_NOTIFICATION', value: "true"), string(name: 'RELEASE_TRAIN_VERSION', value: service_commons_dependencies_version)])The new release will be picked up by the production pipeline by checking the latest tag creation time in our repository:
String latestTagDateString = sh(returnStdout: true, script: "git rev-list -1 \$(git describe --abbrev=0 --tags) --pretty=oneline --format=%ci | awk 'NR%2==0'")
def proceedWithE2ETesting = wasTagReleasedRecently(latestTagDateString)
@NonCPS
def wasTagReleasedRecently(String lastTagDateString) {
def formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss Z")
def lastTagDateTime = OffsetDateTime.parse(lastTagDateString.trim(), formatter)
def currentTimeMinus2hours = OffsetDateTime.now().minus(2, ChronoUnit.HOURS)
return lastTagDateTime.isAfter(currentTimeMinus2hours)
}If the release of core-test-service was created within the last 2 hours we will deploy it by triggering another pipeline. As the last step, it will run E2E tests. As mentioned above, both testing environments will use a shared codebase for acceptance testing. It can be done by setting up one extra job that will fetch an external repository using this block:
definition {
cpsScm {
scm {
git {
remote {
github("core-e2e-tests", 'ssh')
credentials("token")
branch("master")
}
extensions {
wipeOutWorkspace()
}
}
}
scriptPath("jenkins/core_e2e_tests.gvy")
}
}We chose Cucumber as our main test framework since it will give us unparalleled leverage compared to other choices. Tests are written using natural language in a way that allows for troubleshooting to be done basically at a glance. For example here is the scenario that tests the libraries responsible for sending messages in our platform exposed via HTTP endpoint:
Scenario: Should have a working API endpoint for creating a message
Given an object with generated id and message: This is a test
When making a POST call on messaging endpoint with the body containing the given object in JSON representation
Then should result in a 201 response status code
And should receive an empty bodyThe above, combined with this generated report, is a joy to work with.

Furthermore, we decided to create a dedicated slack channel to notify us about the new releases and test results.
So after getting this message
Sanity checks for new release train X.Y.Z on env:
* REST API simple entity integration ✅
* REST API dated entity integration ✅
* REST API auditable entity integration
* Messaging integration ✅
* Messaging FIFO integration ✅
* Storage integration ✅
* Health integration ✅
* Metrics integration ✅
* Logging integration ✅We can finally get our much-needed stress-free beauty sleep, not that it will help us much, right? Hopefully, this small article will get you in the mood for some nice automation work in your company. Have fun and enjoy your peaceful nights.
A short review of the new Pattern property in net/http.Request
A short trip around the AUTO1 Application Cockpit data model
What I present today is how to use police techniques and their mindset to detect and solve bugs in...
